
NEBULUM.ONE
Build RAG AI Systems Without Code
Discover how to create powerful AI applications using RAG technology that combines real-time data retrieval with AI generation for more accurate, contextual responses.
Transform Your AI from Static to Dynamic with Real-Time Knowledge Enhancement
Ready to dive deep into RAG? Watch our comprehensive video tutorial below, then continue reading for detailed implementation steps, code examples, and expert insights that will help you master Retrieval Augmented Generation.
In this comprehensive guide, we’ll explore RAG (Retrieval Augmented Generation) and why it’s becoming essential for modern AI applications. If you’re looking to build your own RAG applications without coding, this tutorial will walk you through every step of the process, from basic concepts to practical implementation.
If you want to get your hands on the bubble.io AI LLM template you can get access to it here.
What Is RAG and Why Does It Matter?
Think of RAG as giving your AI a research assistant. Instead of relying solely on its training data, RAG allows your AI to pull in fresh, relevant information from external sources right when it needs it. This means your AI can provide more accurate, up-to-date, and contextually relevant responses by combining its built-in knowledge with real-time data retrieval.
“RAG bridges the knowledge gap by connecting your AI to real-time data sources whenever it needs current information.”
Critical Problems That RAG Solves in Modern AI
RAG tackles three critical AI limitations that hold back most applications today.
First, there’s the knowledge cutoff problem. Ask your AI about yesterday’s stock prices, this week’s weather forecast, or the latest iPhone features, and it’ll confidently give you outdated or completely made-up information. This happens because AI models train on massive datasets – code repositories, books, websites, conversations, scientific papers – but once training finishes, that knowledge freezes at a specific cutoff date. This creates a dangerous knowledge gap where your AI becomes less reliable over time.
RAG bridges this gap by connecting your AI to real-time data sources whenever it needs current information.
Second, AI models struggle with specialized knowledge. While foundation models know a little about everything, they lack depth in niche domains. Quality datasets for specialized fields simply aren’t publicly available, causing general AI models to stumble when handling industry-specific questions or technical expertise.
RAG fixes this by letting you augment your AI with domain-specific information from expert sources and specialized databases.
Third, AI has no access to your private data. It doesn’t know about your upcoming product launch, your company’s internal processes, or your personal schedule this week. That information lives on your systems, completely invisible to general-purpose AI models.
RAG solves this by providing a seamless way to feed your proprietary data into the AI, enabling it to craft responses that are both accurate and personalized to your specific context.
Real-World RAG Implementation: The Mars Rover Example
Let’s see how RAG works in practice. Imagine building a Mars rover called the Helix250. There is no public information about this rover, so if you search within a standard AI application, the AI would respond:
“It looks like there isn’t any specific information about the Helix250 Mars rover.”
Now, let’s fix that response by uploading up-to-date private information into a vector database. After adding content about the rover’s environmental resilience, communication and navigation systems, and enabling RAG, asking a specific question about the Helix250’s communication system now returns an accurate and detailed response.
Essentially, we just used RAG to fill in this knowledge gap. Here’s how this process works under the hood.
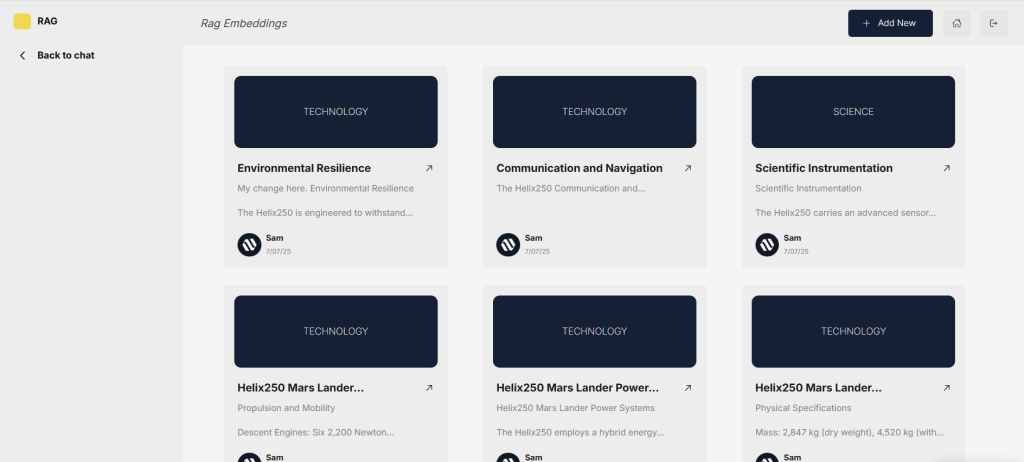
Step 1: Data Ingestion – Converting Information into Searchable Vectors
The first part of the process is data ingestion. In our implementation, the ingesting step takes place through an embedding interface where we’ve set up the application to ingest data efficiently.
Starting with a product description for the Helix250, the first task is to chunk this down into manageable sizes of text. We chunk text for two main reasons:
- To ensure embedding models can fit the data into their context windows
- To ensure the chunks themselves contain the information necessary for search
Chunking is a topic of its own, but as a general rule of thumb, if the chunk of text makes sense without the surrounding context to a human, it will make sense to the language model as well. From larger documents, we chunk them down by adding each subheading as an individual chunk.
“The key to solving this is passing only the most relevant and well-sized chunks to the LLM, which improves both response quality and latency.”
During the ingestion process, we’re essentially converting the text into a long array of numbers through an embedding model. One technical but important piece of information: the number of dimensions in your embedding model need to match the dimensions of the vector database you’re uploading data to.
In our setup, we use the multilingual-e5-large-instruct embedding model with 1024 dimensions. This means the text input will be converted to a vector with 1024 numerical values, and our Pinecone vector database must be configured with the same number of dimensions.
When setting up a database in Pinecone, you simply name your database, select your model (ensuring it’s a dense vector type), select ‘serverless’, then choose your cloud provider and region before creating the index.
The Together AI embeddings API converts your text to a vector, while the Pinecone API takes that vector and upserts it to the vector database you created.
Step 2: Smart Data Retrieval Through Vector Similarity
To retrieve data, we return to our conversation interface. When RAG is not enabled, the process works as normal. However, when we enable RAG, several new options become available:
- Category selection for targeted searching
- RAG activation toggle
- Top-k value setting (determining how many similar results to return)
The top-k value is crucial – if set to 1, only the single most relevant record returns. If set to 10, ten of the most relevant records come back. However, more isn’t always better, as it could decrease relevance and increase context window usage, resulting in slower and more expensive AI runs.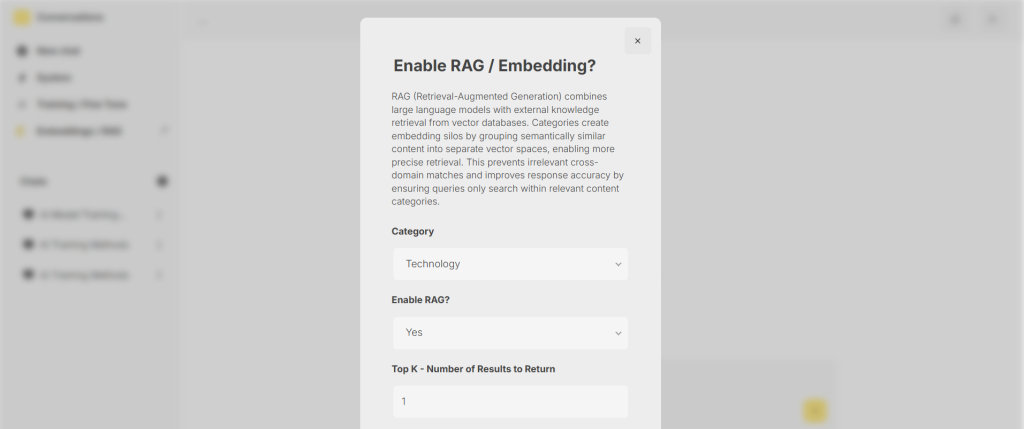
There’s no one-size-fits-all approach here. As a developer, your goal is to right-size the data for the model you’re working with. Each chunk should contain relevant information, but if chunks are too large or too small, you risk reducing search precision or missing valuable context.
For models like Claude 4 Sonnet or GPT-4 o1 with 200k context windows, you may fit entire unchunked documents. However, larger chunks can lead to increased latency and higher costs. Additionally, long-context embedding and LLMs often struggle with the “lost-in-the-middle” problem—where relevant information buried deep in lengthy documents gets overlooked.
For testing purposes, I suggest setting top-k to a lower number, perhaps between 1-5.
Step 3: Generation and Augmentation – Combining AI with Retrieved Knowledge
When RAG is enabled, the query doesn’t get sent directly to the AI model. Instead, the query first needs conversion into a vector format. This step is required because vector databases work by comparing numerical representations of meaning.
To ensure accurate comparison, we need to match formats: since records in our vector database are stored as vectors, we must transform the prompt into the same format. This allows systems like Pinecone to calculate semantic similarity and retrieve the most relevant records based on proximity in vector space.
Once the query has been embedded, we perform a Pinecone search. Pinecone returns a list of related records from the vector database, ranked by relevance based on semantic similarity. Because we attached the original text content as metadata to each vector, we can retrieve that metadata with the response.
Now that we have a response from Pinecone, we can augment our prompt with that response. This works by hitting the AI API as normal, but our prompt gets broken down into two parts: the query (the user’s question) and the knowledge segment (results from the vector database).
The AI is now fed not only the initial question but also additional non-public knowledge from our vector database to make its response higher quality, up-to-date, and more relevant.
Why Choose RAG Over Traditional Model Training?
You might wonder why use RAG over training a model on your data. There are several compelling reasons, though the choice depends on your specific use case.
RAG excels in accessing real-time data. Adding new data to a RAG system takes seconds – you simply upload your data and it’s immediately available. With trained models, any time your data evolves, the model needs retraining or fine-tuning to stay current.
Imagine having to retrain an entire model every time you made an update to the Helix250 Mars Rover—that would be costly, time-consuming, and inefficient. RAG offers a more dynamic alternative, allowing the model to access and use fresh data in real time without requiring constant retraining.
Another benefit of RAG is that it often allows you to work with smaller and cheaper models. Rather than relying on the largest and most expensive models, RAG can make smaller, more specialized models more effective.
Getting Started with No-Code RAG Implementation
The four steps of RAG – ingestion, retrieval, augmentation, and generation – can be implemented without extensive coding knowledge. Modern no-code platforms handle the heavy lifting, saving weeks of development time.
These templates work out of the box after inserting your API keys and can be modified extensively. You can use whatever AI models you prefer – ChatGPT, Claude, DeepSeek, Mistral, Llama, and countless others.
For those new to no-code tools, our specialized AI incubator program can teach you to build high-tech applications from scratch without traditional coding knowledge.
RAG represents a significant advancement in AI applications, offering a practical solution to the limitations of static AI models. By implementing RAG, you’re not just building smarter applications – you’re creating AI systems that can grow and adapt with your data in real time.

Build Your Next Project With Nebulum
Hi! We're Nebulum and we can build pretty much anything you can dream up. Reach out to us today to get the conversation started. Even if you're just pressure testing an idea, we'd be happy to chat.
![]() We build with heart
We build with heart
LET'S TALK
Discuss Your
Hardware & Software
Needs With Us
OUR NEWSLETTER
MACHINES
Embedded Systems
Machine Intelligence
Machine Learning
Sensor Systems
Computer Vision
@NEBULUM 2026. ALL RIGHTS RESERVED
