
NEBULUM.ONE
Fine-Tuning AI Models Without Code
Learn how to fine-tune custom AI models without coding using Together.ai, LoRA training, and no-code tools. Complete step-by-step guide to creating personalized AI applications.
Custom AI Training Without Programming | Fine-Tuning Guide
Ready to take your AI customization beyond basic prompts and RAG? In this comprehensive tutorial, we’ll show you how to fine-tune AI models without writing a single line of code. Using platforms like Together.ai and no-code tools, you’ll learn to create truly custom AI that’s trained specifically for your needs.
Watch the full walkthrough below, then dive into the detailed step-by-step guide that follows. By the end, you’ll have your own fine-tuned AI model integrated into a working application.
We’ve covered the fundamentals of AI customization in earlier posts—crafting system prompts and implementing RAG to give your AI a distinct voice while connecting it to your private, domain-specific data. These techniques transform how your AI responds, but there’s still a crucial limitation: the underlying model remains generic, kind of vanilla, trained on broad knowledge rather than your specific needs. And it knows very little about your primary intentions.
So in this tutorial we’re going to take customization to the next level. We’re going to do this by not only engineering the perfect prompt payload, but now we’re going to fine-tune the AI model itself. This means that we’ll be able to control both what we send to the model as well as how the model processes that information. When we do this, every component of our AI pipeline becomes tailored to our exact requirements.
Best of all, we can do all of this without having to write a line of code.
This is nothing short of an AI superpower
Now for those of you who don’t know, we’re Nebulum – a technology company that does three things: we build a portfolio of high-tech applications, we develop a suite of software tools—including open-source solutions—and we teach developers how to create sophisticated applications without traditional coding.
If you’re interested in expanding your AI capabilities, we offer comprehensive courses on both no code AI development as well as no code AI agent architecture. You’ll find links to both over on our homepage.
So let’s jump in.
Setting Up Your No-Code AI Development Environment
As in the previous tutorials, I’m going to be using this no-code AI template. This template gives us a great jumping off point to build AI applications. For example, in our previous tutorial I showed you how the template does some things that are kind of complex in Bubble, like real time markdown streaming for example. The bubble template also comes with built in RAG connections, so you can upload chunks of private data for your AI to add to its knowledge base. So I’m not going to cover those topics again, but I have linked to those tutorials below.
So today what I want to do is discuss this training or fine turning feature and specifically I want to talk to you a little bit more about how we can train or fine tune or models without having to code.
It’s not as difficult as you might think and at Nebulum we’ve actually built some tools and even developed some plugins to make the process of fine tuning an existing AI model even easier. So let me show you how this works.
Choosing the Right AI Model Training Platform
First of all, as a developer or no-code developer you’ll need to find a model to train. I love the idea that we can train open source models, so that’s what we’re going to be doing in this tutorial. For training infrastructure, two excellent platforms stand out: Fireworks.ai and Together.ai. Because I was working with together.ai in my previous tutorials, I’m going to continue using them in this tutorial, but in the AI LLM template that we’re using there, both fireworks and together are built into the platform out of the box.
Okay, so let’s login to together.ai here. If you’re new to together, you get some free credits when you sign up. So you can test out these models for free. And pennies go a long way here. This represents one of the most compelling advantages of open source models. Performance is on par, often even better than closed source models like Claude or ChatGPT, but the costs are substantially lower. So if you’re trying to scale an AI application, together or fireworks are both really affordable options.
How to Start Fine-Tuning AI Models Without Code
So over in together, what we’re going to do, is we’re going to click on “fine tuning”. Then we’re going to click on “start a new job”. Okay, a couple of things here. We can train any model we want from this dropdown list. However, not all trained models have serverless endpoints. As you can see, in together’s documentation it’s mentioned that there are only 4 models which run serverless LoRA inference. The good news is that these are great models, so it will give us enough to work with. Again, if you want alternative models, you can check out fireworks for more serverless options. Essentially, at the end of the day, what we’re looking for here is an API endpoint to easily connect with after the training is done.
Also, we’re just focused right now on getting this setup. We’re trying to confirm that we can make the link between our app to the trained model. One important thing to keep in mind here is that training models and fine tuning can be expensive. So to keep costs low, we’re going to use the smallest models for our initial tests. For now, this llama 8B mode will work perfectly. This will just cost us a few cents to train.
The reason why this is important is because generally AI model training is iterative. It’s not like RAG, you normally don’t get it right on the first try. It takes some tweaking to get right, based on the model you chose, the data you upload as your training data as well as the parameters you set. Therefore, while you’re sorting out the kinks, always just start with small models to keep costs low.
Okay, so back on our fine tuning page, we can now select this model. Once we do that it’s going to ask for a training file. So this is where a lot of people get confused. Because you can’t just upload documents or text. It doesn’t work like RAG or vector databases which we setup in the last tutorial. When training a model, there are training data conventions that we need to follow.
Understanding JSONL Training Data Format
The training data must be formatted as a JSONL file (JSON Lines). This format contains multiple JSON objects, with each line representing a single training example.
Each line follows a conversation structure: a user prompt paired with an assistant response. The key insight here is that the assistant responses aren’t AI-generated—they’re your ideal responses. These examples represent exactly how you want your fine-tuned model to sound, behave, and respond to similar queries.
Most training datasets use human-written assistant responses, crafted to demonstrate the specific tone, style, and knowledge you want your model to learn. This is where you define your AI’s personality and expertise.
Now in order to make this work, all we need to do in this template is to go to our training page, and add a training pair by clicking on this button here. Then from here, we can add a user prompt here and a corresponding system output here.
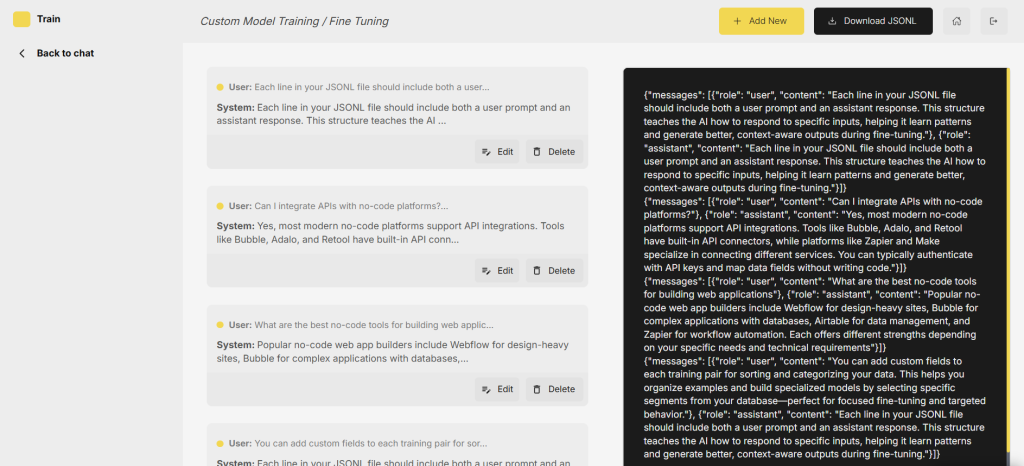
Optionally, you can create categories or filters in your bubble.io backend so that you can show different training pairs based on what you’re trying to do with the model. For example, you might add tweets under a tweet category, research under the research category and so on. This can be as simple or robust as you need. Categories serve purely as organizational tools within your workspace. When you export training data, only the essential prompt-response pairs transfer to the model. The categorization system helps you manage and filter your training examples but doesn’t affect the actual training process.
So notice that once we add a training pair, it becomes visible here. But most importantly, the JSONL formatting has been done for us over to the right. For demonstration purposes, let’s just add a few more training examples and then after that you’ll see that our JSONL file is starting to populate with training data.
Optimal Training Data Size for AI Fine-Tuning
Now in terms of training data size, there are some important things to get right here. You’re going to need to have a minimum of 3 training pairs and a maximum of 3,000,000. Together doesn’t show a recommended size here, but over on fireworks they do. And they say that the recommended size of your dataset should be between 100 to 100,000 examples.
Too few examples risk underfitting—the model won’t learn sufficient patterns. While large datasets aren’t inherently problematic, they require careful curation to maintain quality and avoid bias. The sweet spot of 100-100,000 examples typically provides enough diversity for good generalization without becoming unwieldy to manage. The key is data quality and diversity, not just quantity.
So once you have those training pairs added to your database, you’ll be able to click on this button here which says download JSONL. With this on your computer, you can now jump back to together.ai and upload the training document.
Configuring LoRA Settings for Cost-Effective Training
Next, you’ll need to create a suffix—a custom identifier that gets appended to your model’s API endpoint. This suffix serves as a unique name for your fine-tuned model, making it easy to distinguish from other models in your account.
Choose any descriptive name that helps you identify this specific model. For example, you might use “customer-support-v1” or “technical-writer” depending on your model’s purpose.
Now, under ‘training type’ we’re going to select ‘lora’. We don’t want to re-train the full model. In a nutshell, LoRA (Low-Rank Adaptation) is a parameter-efficient fine-tuning technique that adapts large language models by training only small additional matrices instead of all parameters. Again, this makes our training significantly faster and substantially cheaper.
Most default settings work fine, but you’ll want to adjust the epochs setting. Mine is currently set to 1, but this represents complete passes through your training data—one epoch means the model sees each example once.
In my experience, one pass isn’t sufficient for proper learning. Setting epochs between 3-5 generally works best. Fireworks defaults to 5, which typically ensures training data gets properly absorbed.
However, setting this too high causes overfitting—the model will start performing poorly. This is one setting you’ll need to experiment with, as fine-tuning is an iterative process requiring some trial and adjustment.
Running Your AI Model Training Job
All of the other settings here look good. Now we can just click on ‘create job’. Here we’ll be asked to confirm our settings, we can do that then click on ‘start job’. From there the status will change to “pending” and then shortly after that it will change to ‘queued’. You can then follow the progress by clicking on ‘all events’ here. Shortly after that, you’ll see the status change to ‘running’. Now you’ll need to wait 5 – 10 minutes, maybe a bit more depending on the model you chose, the training set you uploaded. But training is normally pretty quick. So let’s hold tight and we’ll jump back once this fine tuning session is complete.
As you can see, the job is done, it just cost me a few cents to run. But now, the amazing news is that I have a custom trained model that I can access through my no-code bubble application. But just before doing that, let’s make sure it all worked by testing it out in the playground. This would be a good way to make sure your training data got absorbed into the model.
Once we do that, we’re ready to move over and place this within our Bubble app.
Adding Custom Model to Bubble
To get access to our custom trained model’s serverless endpoint, click on ‘fine tuning’ and then click on the fine tuning job you want to use. Next, scroll down until you see this option for ‘run serverless LoRA inference’.
Here you’ll see a custom url including your username and the suffix that you chose in the previous step. So we’ll just copy that entire URL, then jump back into this bubble template. From here, we’ll click on plugins, then ‘API connector plugin’, then we’ll head over to our API calls.
Remember, from previous tutorials, we actually have two api calls here. One for new chats and one for ongoing chats, so we need to add this model URL to both of those API calls. Then we simply need to re-initialize the call. Then once that’s done, we can communicate with our custom AI model directly from within our own application.
This is Groundbreaking
We’ve achieved complete customization of the AI process—from input engineering to model training—entirely through no-code tools.
What’s remarkable is that we’ve now optimized the entire AI pipeline. Our payload includes precision-engineered system messages, targeted prompts, complete chat history, and relevant RAG embeddings—every input is carefully crafted.
The game-changer is what happens when we hit submit. Instead of sending this payload to a generic vanilla model, we’re now interacting with our custom-trained model, fine-tuned on our specific data.
Conclusion
If you’ve found this tutorial valuable, and you want to pick up the exact template I’ve used in this tutorial, a link to this template can be found here.. You could of course build something like this from scratch within bubble, but it would take you many days, potentially weeks to build. So the template just acts as a great jumping off point for further customization work which would allow you to tweak it to meet your own specific needs.
Lastly, if all of this seems exciting to you, but a bit over your head, we actually have an online no-code AI training incubator program, where we’ll teach you how to bring your AI application ideas to life, without having to write code. So again, if that sounds interesting to you, I’ve left a link to our course as well as a coupon code below.
Or if you’re less of a do-it-yourselfer and you want to get someone to bring your AI idea to life, just reach out to us at Nebulum. Let us know what you’re trying to build. We’d be happy to take a look.
Thanks for reading!

Build Your Next Project With Nebulum
Hi! We're Nebulum and we can build pretty much anything you can dream up. Reach out to us today to get the conversation started. Even if you're just pressure testing an idea, we'd be happy to chat.
![]() We build with heart
We build with heart
LET'S TALK
Discuss Your
Hardware & Software
Needs With Us
OUR NEWSLETTER
MACHINES
Embedded Systems
Machine Intelligence
Machine Learning
Sensor Systems
Computer Vision
@NEBULUM 2026. ALL RIGHTS RESERVED
